프로젝트 요약
- 한 줄 요약: 매트릭/로그/트레이스를 한 화면에서 연결해 보고, 이상 징후는 알림으로 선제 감지하도록 모니터링 체계를 구축했습니다.
- 진행/소속: 파트타임스터디
- 키워드:
Prometheus,Grafana,Loki,Tempo,OpenTelemetry,Notification
문제(AS-IS)
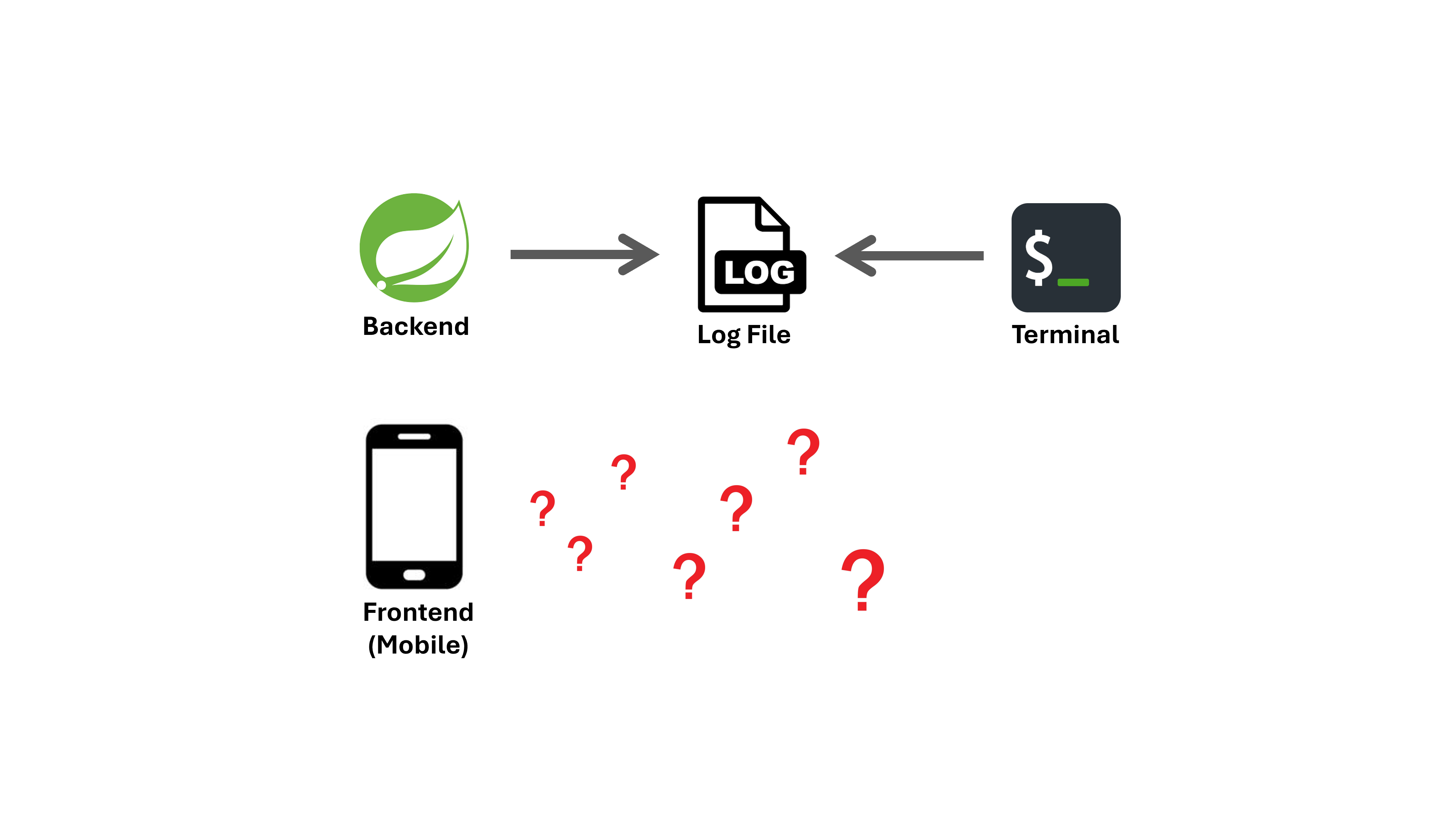
- 트래픽 증가로 서버 리소스 부족 이슈가 발생해도 조기 감지가 어려움
- CS로 유입되지 않으면 이슈가 누락될 수 있음
- 로그 확인을 위해 서버에 직접 접속 후 확인해야 함
- 재발 여부 확인 또한 주기적 수동 점검에 의존함
- 프론트 이슈 발생시 로그 조회 어려움
목표(TO-BE)
- 서버 리소스 모니터링을 위한 매트릭 수집 및 대시보드 구축
- 이상 징후(500/예외 등) 발생 시 잔디 알림 자동화
- 이슈 상황을 더 빠르게 파악할 수 있는 관측(로그/트레이스) 체계 구축
- 재발 모니터링 자동화 및 분석 속도 개선
설계/선택(Key decisions)
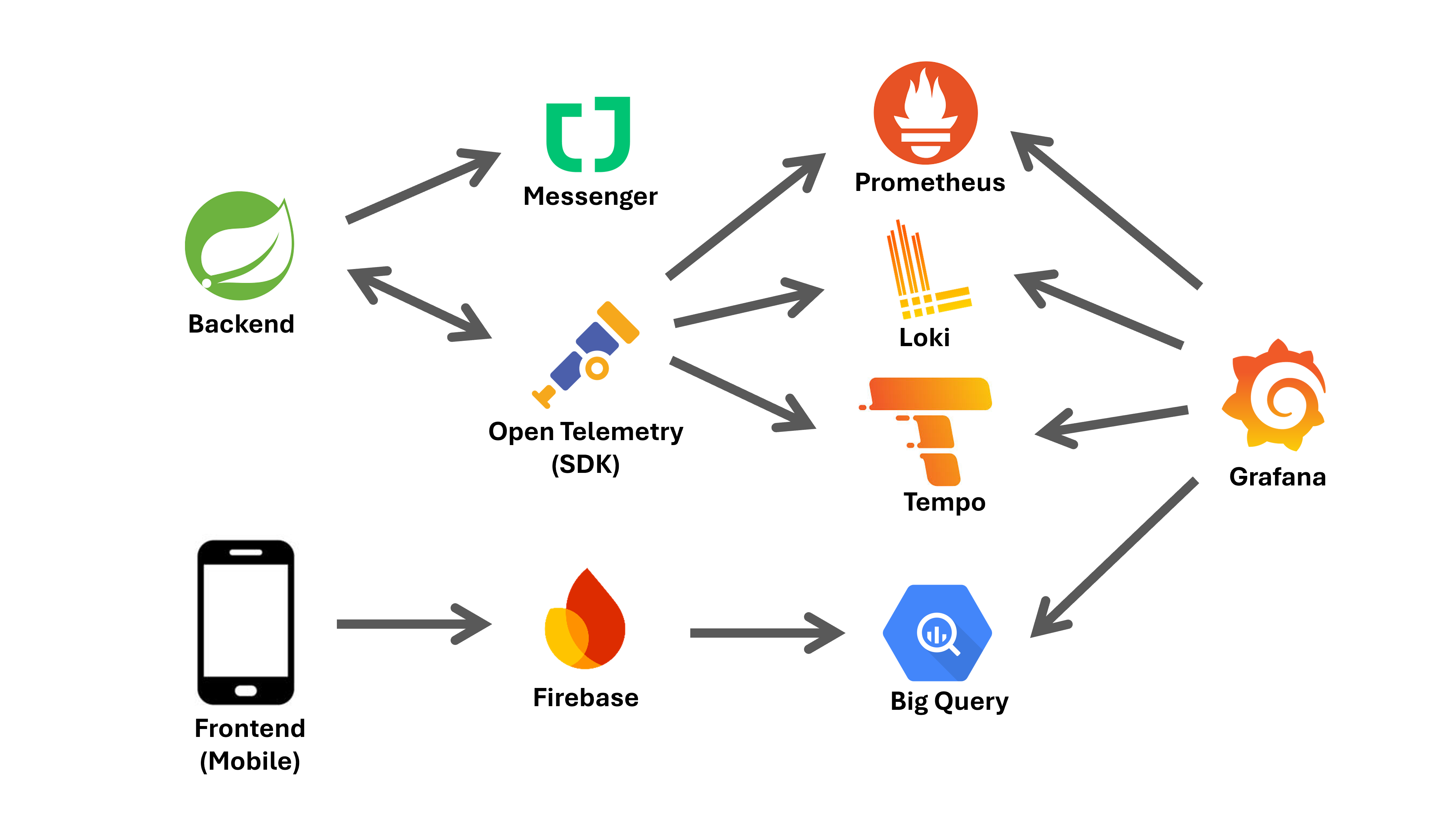
- Alerting: 미처리 예외 발생 시 잔디 알림(HTTP/비동기작업 예외 핸들러 처리)
- Instrumentation:
OpenTelemetry SDK로 지표 수집 및 문맥 추적 간편화 - Metrics:
Prometheus+Grafana로 매트릭 수집 및 대시보드 구성 - Logs: 서버 로그는
Loki, 프론트 예외 로그는Firebase→BigQuery로 수집 - Traces:
Tempo로 트레이스 연계, 재발 예상 지점 분석 간편화 - Query UX:
Grafana에서 유저/시간대 기준으로 쉽게 조회할 수 있도록 구성
결과(Impact)
- 선제적 이슈 감지: 대시보드/알림으로 CS 유입 전에 리소스 서버 예외 발생을 인지하여 누락 가능성을 낮춤
- 원인 분석 시간 단축: 서버 접속 없이 Grafana에서 유저/시간대 기준으로 로그·매트릭·트레이스를 한 화면에서 연결 조회
- 재발 모니터링 부담 감소: 수동 점검 대신 트레이스 기반 재발 예상 지점 알림으로 확인 흐름을 단순화
- 대응 속도 개선: “알림 수신 → Grafana에서 연계 조회” 흐름이 정착되며 체감 MTTR이 감소
구현 상세
1) Alerting: 잔디 알림
- Global Exception Handler에서 서버 예외 발생 시 잔디 메시지 전송 및 500 반환
- Async Exception Handler에서 예외 발생 시 잔디 메시지 전송
- 이슈 재발 예상 지점에 잔디 알림을 추가하여 혹시 모를 이슈 재발 방지
- 메시지 전송은 비동기로 구현하여 응답 시간 영향을 최소화
2) Instrumentation: OpenTelemetry SDK
- 매트릭을 포함한 지표를 간단히 수집하여 전달하고 문맥 추적을 간단히 적용하기 위해 사용
3) Metrics: Prometheus + Grafana
- Prometheus 도입 및 Grafana 대시보드 구성
- 주요 수집 항목
- 서버 리소스: CPU(Load Average), Memory(Usage), Disk(Usage/I/O)
- API 응답 코드별 count
- Database 쿼리 latency
- JVM memory
4) Logs: Loki + Grafana, Firebase(Bigquery)
- Loki를 사용하여 로그 저장 및 Endpoint 인덱싱
- Grafana 변수(유저/시간대)를 활용해 로그/매트릭을 빠르게 좁혀보는 조회 경험 구성
- 프론트에서도 소멸시키던 예외를 Firebase로 전송하도록 제안
4) Traces: Tempo
- 필요 시 trace를 Annotation으로 지정해 이슈 재발 탐지에 활용
어떠한 날카로운 피드백이더라도 환영합니다. 사소한 의견도 괜찮습니다.
citron0137@gmail.com 또는 LinkedIn 을 통해 피드백을 보내주세요.